몇몇 분들의 요청으로 간략하게 적어보겠습니다만...
제가 UML을 정식으로 배운 것도 아니고 그냥 대충 제멋대로 이해하고 사용하는 것 이기 때문에
실제 정석으로 배운 분들이 보기에 여러가지 잘못된 점이 많이 있을겁니다.
잘못된 부분이 보이거나 의견이 있으시다면 코멘트로 달아주시면 감사하겠습니다.
잘못된 점을 수정하고 좋은 조언을 달게 받아 수정을 하겠습니다.
아참... 스크롤의 압박이 무지 심합니다.
일단 StarUML 프로그램 다운로드 링크입니다.
http://sourceforge.net/projects/staruml/files/staruml/5.0/
프로그램을 다운받아서 설치하시면 되겠습니다.
비지오로 사용하시는 분들은 비지오로 하셔도 무관합니다.
UML로 클래스 다이어그램을 그리는 목적
왜 우리는 클래스 다이어그램을 그려야 하는가.
소스코드를 작정해 놓고 그것만 보고서 구조가 어떻게 되어있고 동작이 어떻게 이루어 지는가를
알아내기는 무척 어렵습니다.
하지만...
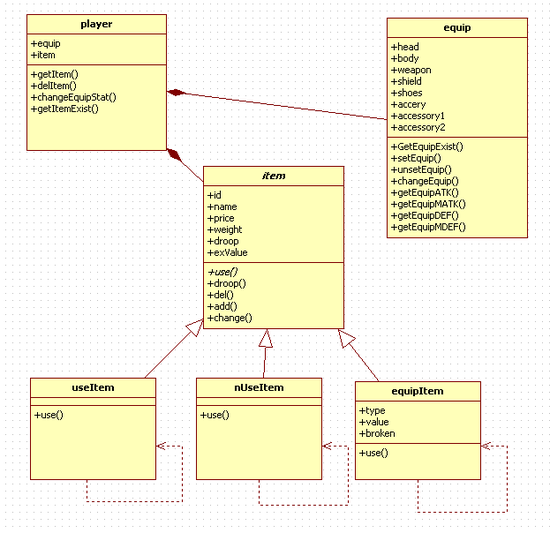
이정도만 보면 대충 어떻게 되는지 알 수 있지 않을까요?
여튼 직접 코드를 짜지 않고서도 구조를 어느정도 미리 그려보는 용도도있고
타인이 코드를 직접 분석하는 것 보다 이렇게 다이어 그램을 통해 어떻게 돌아가는지
알 수 있기도 하고 그 외에도 여러가지 이점이 많습니다.
자~ 그럼 이제부터 하나씩 파보도록 하겠습니다.
일단 클래스입니다.
클래스를 만드는 것은 매우 간단합니다.
클래스를 선택하고 드래그 하면 끝이니까요.
그리고 변수와 함수들을 추가해 줍니다.
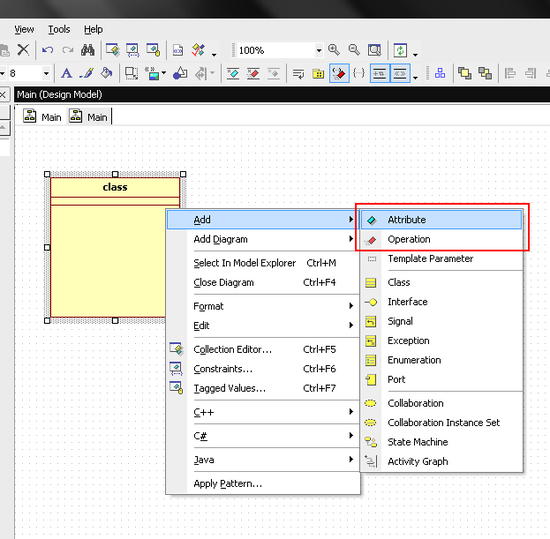
클래스에 마우스 커서를 대고 오른클릭을 하면 메뉴가 뜹니다.
변수와 함수를 각각 추가해 줍니다.
아참
생성한 클래스명 변수명 함수명은
더블클릭을 하면 아래 그림처럼 에딧창이 나타나면서 변경이 가능합니다.
이녀석의 이름을 바꿔주고 구성품 클래스를 하나 만들어 보겠습니다.
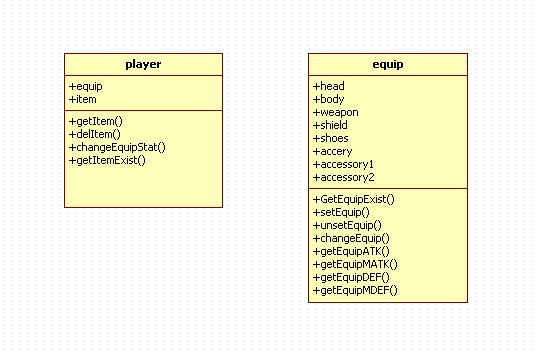
player는 equip를 가지고 있습니다.
하지만 처리를 좀 원할하게 하기 위해서 클래스로 만들었습니다.
그리고 player가 소유한 변수중에 equip라고 있는게 보이시죠?
좀 더 쉽게 예를 들어볼까요?
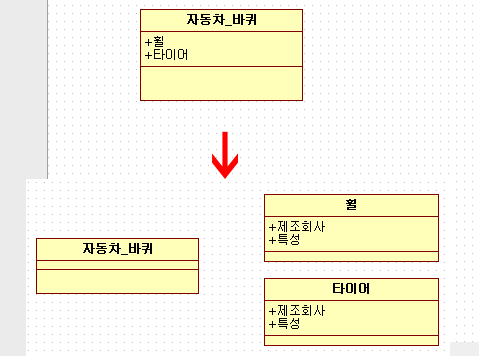
자동차 바퀴라는 클래스에
휠과 타이어라는 변수가 있습니다.
하지만 휠과 타이어는 각각 여러가지 속성이 존재하죠
제가 차 바퀴에 대해 잘 몰라서 제조회사, 특성 이라고만 적어 놓았지만
타이어의 경우 스노 타이어인지 차종이나 크기 등은 어떤거에 맞는 것인지 등등
여러가지 속성이 있습니다.
그런 모든값을 자동차 바퀴 라는 클래스에 몰아넣는 것은 별로 좋은 생각이 아니라고 봅니다.
그래서 따로 클래스를 만들어서 자동차 바퀴라는 클래스에 포함시키는 것이죠
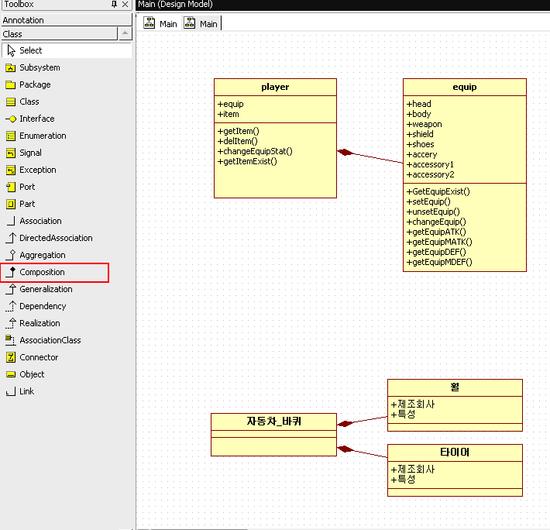
뭐 간단하고 친절하게 composition이라고 쓰여저 있는걸 선택해서 둘을 이어주면 됩니다.
그 위에 Aggregation이라고 속이 빈 마름모가 보일겁니다.
이건 아주 살짝 다릅니다.
차이점이 하나 존재하거든요
바로 그 클래스가 릴리즈되는 시점의 차이 입니다.
composition의 경우 소유하는 클래스가 죽을때 소유당하는 클래스가 같이 죽지만
aggregaton의 경우에는 소유하는 클래스가 죽을때 소유당하는 녀석들이 같이 죽지 않는다는
차이점이 있습니다.
aggregation의 경우에도 클래스가 다른 한 클래스를 보유한다는 것에는 차이가 없습니다.
하지만!
속이 빈 마름모로 연결을 해 놓을경우 자식(?)보다 부모(?)가 먼저 죽을 수 있습니다.
예를 들면 다음과 같습니다.
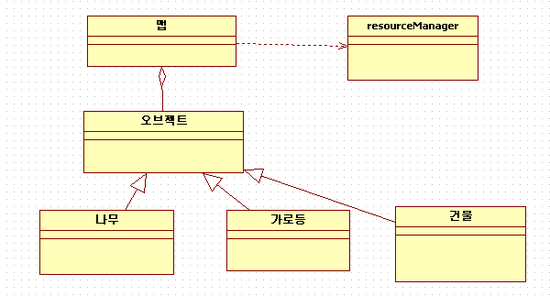
맵을 띄울때 맵이 가진 요소들이 있을겁니다.
예로 나무 가로등 건물 등이 있다고 가정하죠
이때 맵은 분명히 오브젝트들을 소유하고 있습니다.
하지만 오브젝트를 읽어서 초기화 하고 삭제하는 일은 맵이라는 클래스가 하지 않습니다.
맵은 리소스 관리자 클래스에게 오브젝트를 읽어달라고 하고 포인터를 받아서 소유합니다.
맵이라는 클래스에서 release라는 함수를 불러서 자신을 릴리즈 할 경우에도
리소스 관리자에게 오브젝츠들을 릴리즈 해달라고 요청하지 않는 이상 오브젝트들은 살아남습니다.
오브젝트들은 자기 소유자가 죽더라도 자신은 죽지 않습니다.
소스코드로 보면 좀 더 이해가 잘 되실까 해서 간단히 적어보겠습니다.

aggregation의 경우 다른 클래스에게서 리소스를 읽어달라고 요청하고 포인터만 받아서 사용하고
자신이 리소스를 릴리즈 하지 않습니다.
하지만 composition의 경우 자신이 직접 리소스를 읽어서 사용하고 자신 스스로 해제해 버립니다.
클래스 자신만 쓰고 버리면 그만인 경우에도
리소스 관리자에게 한번 읽었으면 지금 당장은 사용하지 않더라도 나중에 다시 사용할 일이 있으면
현재 사용하는 리스트만 초기화 해버리고 메니저에게 일일히 해제하라고 이야기 하지 않는 경우가
많이 있습니다.
자주 사용하는것은 남기고 크기가 크거나 자주 쓰지 않는건 물론 자주 릴리즈 해야겠지요
이야기가 삼천포로 좀 빠졌지만...;
다시 돌아와서
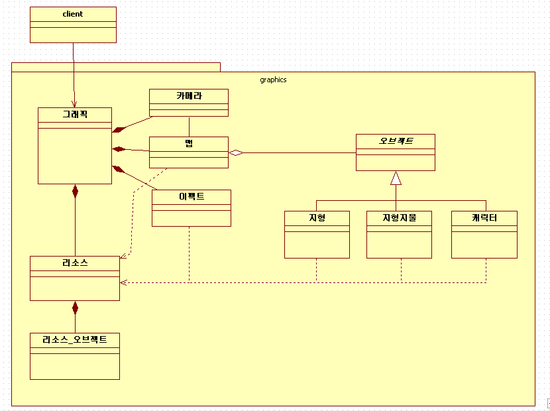
이번엔 좀 큰그림을 그려놓고 설명하겠습니다.
일단 graphics라는 package를 하나 바닥에 깔아놓은 것이 눈에 띄죠
저녀석은 namespace입니다.
우리가 자주 사용하는 것 중에 namaspace std라는 것을 자주 사용하죠
그안에 vector map string 등등 우리가 좋아하고 자주 사용하는 것들이 들어있습니다만
저런 이름들은 자주 사용할지도 모르기 때문에 사용하는 것 입니다.
제가 위에 그린 예제도 저녀석들은 하나의 라이브러리로 만들어 놓았다고 가정할 경우
리소스라는 클래스가 있습니다만 물론 gsResource라던가로 하겠지만
혹여 어떤사람이 gsResource라는 클래스를 만들어 버린다던가
설마? 하는 문제를 위해서 라는 의미가 일단 가장 큽니다.
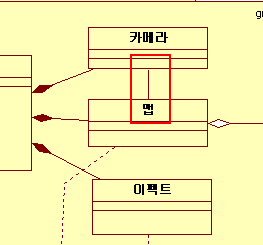
Association 실선으로 이어진 것을 제휴관계라고 하는데요
간단하게 말하자면 '두 클래스가 서로의 정보를 이용한다'라는 정도로 이해하시면 됩니다.
카메라는 자신의 눈에 해당하는 곳의 바로앞에 오게되면 카메라 위치를 강제적으로 옮기거나
못보게 해야하는 곳으로 맞추는 것 등을 방지하던가 맵의 데이터를 많이 사용합니다.
반대로 맵의 경우 카메라의 절두체에 해당하는 곳 밖의 오브젝트들을 그리지 않아야 하고
멀리 있는것이면 폴리곤을 조금 사용하는 대처품으로 교체한다던가 카메라를 강제로 옮기지 않고
카메라의 눈 앞에있는 오브젝트를 반투명하게 한다던가 기타 등등등
카메라의 위치 정보와 절두체 등의 정보를 많이 사용합니다.
서로 상대방이 가진 정보를 사용할 일이 많기 때문에 제휴관계 라고 표시를 해둡니다.
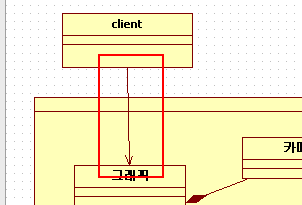
DirectedAssociation 일방적 제휴관계라고 하네요
클라이언트는 graphics라는 녀석중에서 그래픽이라는 facade클래스를 통해 그래픽 데이터를
처리합니다.
일단 이녀석은 라이브러리로서
#include "gsgraphic.h"
pragma commant( lib, "gsgraphic.lib" )
using namespace graphics ;
이렇게 해놓고 쓸 녀석인 만큼 그래픽이라는 클래스에서 클라이언트에 대해 뭔가를 특정하기엔
무리가 있으며 클라이언트쪽에 뭔가 요청하거나 할 일이 없습니다.
클라이언트가 일방적으로 뭔가 넣고 초기화 하라고 시켜서 초기화 하고
말 그대로 하라는 일만 소처럼 열심히 하는거죠
그래서 일방적 제휴라고 하는 것 같습니다.
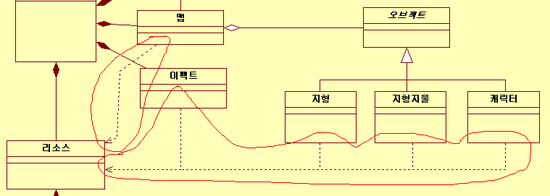
위 그림처럼 점선으로 이어놓은 것을 Dependency 의존관계 라고 합니다.
지형지물이던 맵이던 이펙트던 스스로 리소스를 파일에서 읽는짓은 하지 못합니다.
왜냐구요?
만약 저녀석들이 각각 리소스를 파일에서 읽는 작업을 한다고 가정하면....
5개 클래스 각각 파일을 읽고 파일의 정보들을 구조체에 담고 분류하는일을 갖고 있어야 할겁니다.
5개 클래스에 동일한 코드와 비슷한코드가 똑같이 박혀있는 것부터가 일단 용납이 안되며
리소스 재사용이나 쌓아둔 양에따라 적당히 잘 안쓰는건 릴리즈 한다던가 하는 관리를 위해서라도
리소스를 관리하는 클래스를 따로 두고 관리해야 하지 않을까 합니다.
일단 딴 이야기는 이쯤 하고...;
클래스의 일부 기능을 타 클래스의 힘을 빌려서 해야할 경우에 의존적이라고 하고
저렇게 점선에 화살표로 표기합니다.
그 외에 의존하는 클래스의 변화에 영향을 받기도 한다고 기억하고 있습니다만
리소스를 읽는 과정 자체가 리소스 클래스가 가지고 있고 리소스 객체의 형태가 변한다면
각자 받아온 값을 활용하는 법도 확실히 바뀌는 일이 있을지 모르겠군요

다음은 Multiplicity입니다. 수량이라는 게죠
맵은 반드시 1개가 존재하고 오브젝트는 0개가 될수도 있고 몇개가 될수도 있습니다.
저런식으로 수치를 넣어주는 것 입니다만...
쓰기 나름입니다.
1 - * 이라고 해도 위 그림과 같은 의미이고
1 - 5 라고 하면 반드시 1개와 5개가 맞물린다는 것입니다.
10개짜리 분산서버와 유져들간의 커뮤니케이션은 10 - * 일테고 말이죠
하지만 이것을 꼭 표기해 줄 필요는 없다고 생각합니다.
대부분 1:1로 맞물리는 경우이고 꼭 필요하거나 강조하고 싶은 부분에서만 표기를 하고
당연하다 싶은 부분은 그냥 생략하는게 좋다고 생각합니다.
reflexive 반사?
클래스들은 자기 자신이 자기 자신과 영향을 주고받을 수도 있습니다.
스크롤의 압박도 심하고 머리도 아픈데 여기서 또 이상한게 나왔네
아... 이건 또 뭡니까? 하시는 분들이 계시겠지만 생각보다 간단합니다.
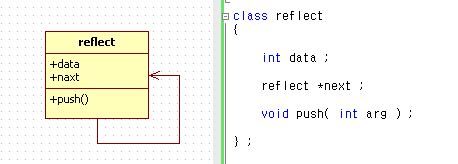
코드 자체는 엉터리지만 그런건 좀 넘어가 주세요...;
이녀석은 자기 자신을 일방적으로 제휴합니다.
next만 알지 자기 이전에 대해서는 알지를 못합니다.
push함수에서는 자기 다음녀석을 생성해서 값을 써 넣는일만 하겠죠
저런식으로 자기 스스로에게 영향을 미치는 것을 반사~ 라고 합니다.
지금껀 반사 일방적 제휴겠죠 reflexive DirectedAssociation
자기 전과 후의 값을 알면 그냥 반사제휴일테고 말이죠 reflexive Association
그 외에 이런것들이 있습니다.
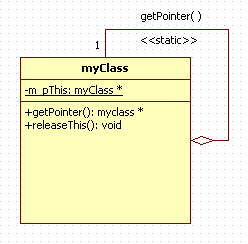
위 그림은 싱글톤 클래스 입니다.
자기 자신에게 연결된 끝이 마름모꼴인 직선을 주시해 주세요
싱글톤 클래스도 반사제휴의 대표적인 예 입니다.
그 외에도 저 그림을 보고 알아야 하는 것이
myClass *test ;
test = test->getPointer( ) ;
위와같이 코드를 짤텐데 말이죠
저녀석이 static 정적 맴버를 사용한 정적 함수처럼 작동하고 있고
싱글톤 클래스의 포인터를 얻고있다는 의미로 getPointer( ) 와 <<static>>를 표기해 주었습니다.
그 다음
-m_pThis: myClass *
밑줄 underbar은 이 변수가 static 정적 변수라는 것을 의미합니다.
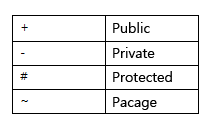
-기호는 이 변수가 private변수라는 것을 의미
맴버 변수의 속성
: myClass *는 m_pThis라는 변수의 변수형이 myClass형 포인터 라는 것을 의미합니다.
함수의 경우
-init( HWND hWnd, int width, int height ) : bool
속성 함수명 인자 : 반환값
위와같은 형식으로 표기가 가능합니다.
음... 거의 끝이 나 가는군요
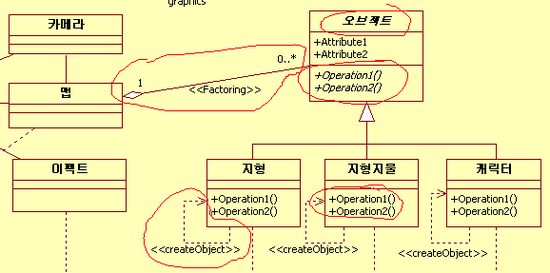
위 그림은 데이터 팩토링에 대해서 나타난 것입니다.
일단 맵과 오브젝트를 잇는 선에 1 - 0.*이라고 해서 한개의 맵과 다수의 오브젝트가 있을 수 있고
<<Factoring>>라고 표기도 해줬습니다.
그리고 지형 지형지물 캐릭터 클래스를 보면 자기 스스로를 의존하고 있는 반사 의존을 표기해
준 상태인데요 저것은 자기 자신의 메모리를 할당해서 되돌리는 함수를 의존한다는 뜻 입니다.
가능하면 <<메모리를 할당해서 되돌려주는 함수명>>으로 하는 것이 좋을 듯 합니다.
오브젝트 클래스를 보면
오브젝트라는 클래스 이름과 operation1( ) operation2( ) 라는 두개의 함수명이
옆으로 살짝 기울어져 있는 것이 보이실겁니다.
일단 클래스 이름이 기울어져 있는 것은
저것이 추상 클래스로서 인스턴스를 생성하지 않을 것이라는 것을 의미하고
함수 두개의 이름이 기울어져 있는 것은 저 함수들이 가상함수라는 것을 의미합니다.
저런식으로 가상함수와 추상 클래스를 표기해서 인터페이스를 그리는 방법도 있겠지만
저는 자바사용자가 아니고 C++에서는 interface라는 개념도 없어서 인터페이스에 관해서는
자세히 모르겠네요 ;ㅅ;
제 블로그에 있는 정보들은 모두 수정 및 퍼가는것을 제한하고 있지 않으며
오른클릭과 Ctrl + C도 먹으니까 자유롭게 활용하시면 됩니다.
그리고 필요하신 것을 요청하시면 가능한 것이라면 도와드리는 주의랍니다.
마음껏 가져가세요~





































































